Code Framework
Usage Modes
PyQuake3D supports two execution backends:
MPI-based CPU backend: Implements a memory-efficient H-matrix representation of the stiffness matrix, distributed across multiple processors using mpi4py. This version is well-suited for simulations with >40,000 elements and optimized for HPC systems.
MPI-based multi-GPU backend: CPUs are used to manage the distributed workload, simulation coordination, and data communication, while GPUs accelerate the most demanding numerical kernels (like large matrix calculations).Hmatrix requires a series of matrix transformations to be suitable for GPU acceleration.
This structure allows users to scale from fast exploratory models on local machines to high-resolution, physics-rich earthquake simulations on supercomputing clusters. The modular design also facilitates extension of the framework to include additional rheologies, boundary conditions, or coupling with geodynamic models. PyQuake3D can be executed either in MPI-based multi-GPU mode (:file:main_gpu_mpi.py) or in MPI-parallel CPU mode (:file:main_mpi.py), depending on the computation resource. All simulations are launched from the project’s root directory using the :file:main_gpu.py and :file:main_mpi.py scripts located in the :file:src folder.
Note
The MPI-based multi-GPU version does not utilize GPU acceleration for fluid-related calculations, but this part of the code is still usable.
Code Structure and File Description
The PyQuake3D source code is organized to reflect its modular architecture and
hybrid parallel computing design (Fig. 4). All core Python
modules are located in the src directory, while model configurations and
parameter files are provided in the examples folder. The examples
directory contains predefined models, including the BP5-QD benchmark based
on the Southern California Earthquake Center’s SEAS community validation
project [https://strike.scec.org/cvws/seas/download/].
The PyQuake3D codebase is structured around distinct computational tasks:
main_mpi.py: Entry point for running the quasi-dynamic simulations based on the MPI CPU backend. It handles the model setup, time integration, and output generation. Users may customize this script for advanced diagnostics or automated post-processing.main_gpu_mpi.py: Entry point for running the quasi-dynamic simulations on the MPI-based multi-GPU backend. It handles the model setup, time integration, and output generation. Users may customize this script for advanced diagnostics or automated post-processing.QDsim.pyandQDsim_gpu_mpi.py: Defines theQDsimclass, which encapsulates the governing equations, numerical integrator, and interface to the selected Green’s function backend.QDsim_gpu_mpi.pyinherits fromQDsim.pyand adds key features such as multi-GPU allocation and H matrix transformation.QDsim.Init_condition(): Setting initial condition of fault model.QDsim.simu_forward(): Model forward calculation.
DH_Greenfunction.pyandSH_Greenfunction.py: Compute the displacement and stress Green’s functions for homogeneous elastic half-space media.TDstressFS_C.cpp: Compute the stress Green’s functions for homogeneous elastic half-space and full-space media using C++.Hmatrix.py: Constructs and applies the hierarchical matrix representation based on Adaptive Cross Approximation (ACA), optimized for distributed-memory parallelism usingmpi4py.create_recursive_blocks(): Recursively build the blocktree.createHmatrix(): Build the Hmatrix.tree_block.master(): Dynamically allocate MPI tasks.tree_block.worker(): Excute MPI tasks of calculating stress green’s functions.tree_block.tree_block.parallel_block_scatter_send(): Distribute sub-matrices of the fully built Hmatrix to each process.
Readmsh.py: Parses unstructured mesh files (in.mshformat) and imports model geometry, fault segmentation, and material parameters.
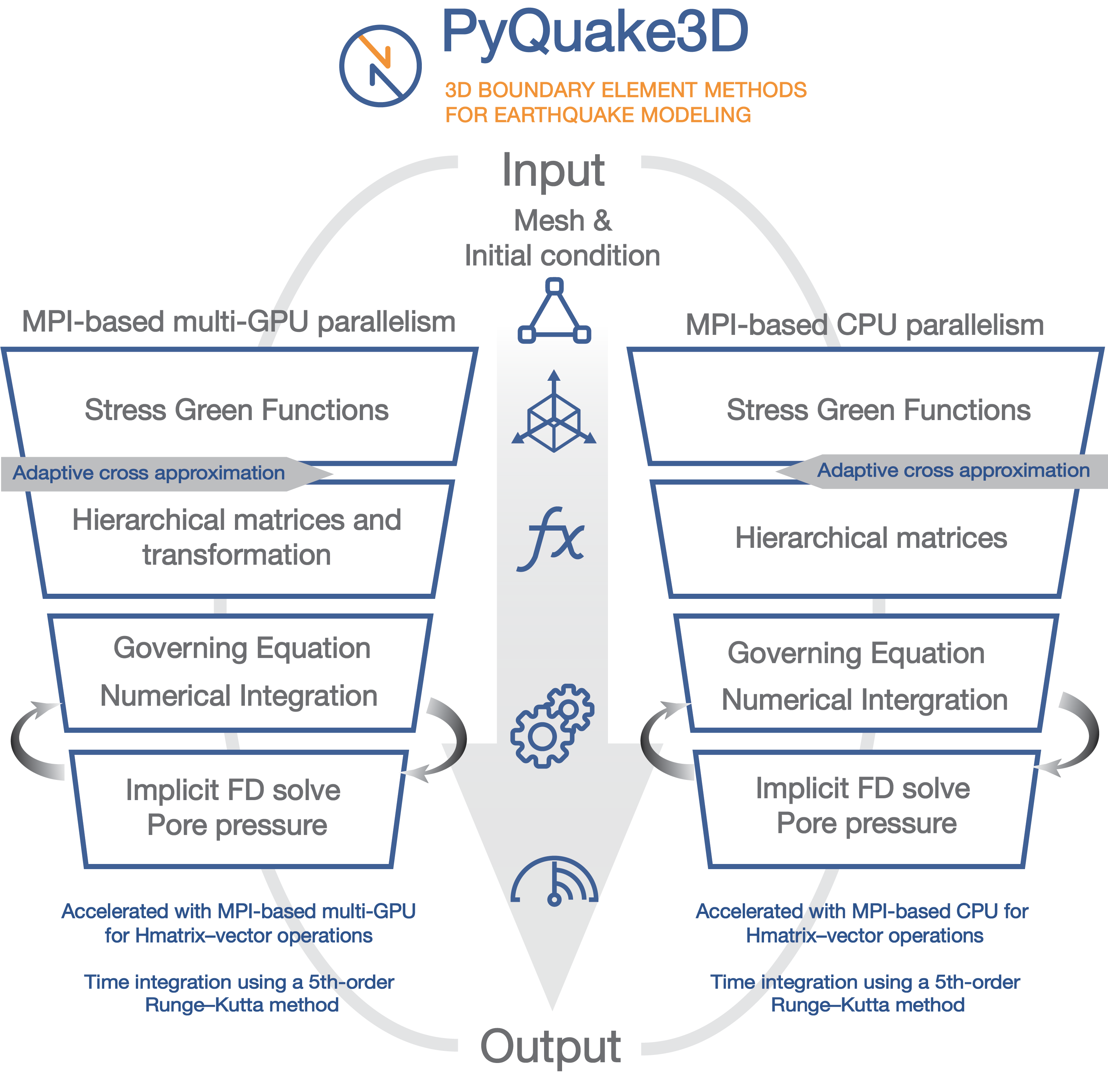
Fig. 4 Overview of the PyQuake3D computational framework. The workflow includes input setup, solver implementation on GPU or CPU architectures, and output diagnostics. The GPU version uses Hmatrix–vector operations accelerated with CUDA, while the CPU version applies hierarchical matrix and MPI-based parallelism.