Theoretical background
Governing Equations for Quasi-dynamic Model
In this section, we first present the governing equations of the classical quasi-dynamic seismic cycle and the boundary element method used to solve them. We then discuss shear-induced dilatation and the thermal pressurization process caused by frictional heating, and introduce the finite difference method employed for their numerical solution. Finally, we provide detailed descriptions of the Hierarchical matrix (Hmatrix) method and the Lattice Hmatrix method.
To solve the earthquake dynamic simulation problem using boundary integral equations, we assume that the fault plane is embedded in an elastic half-space or full-space with homogeneous and constant elastic moduli. A constant tectonic loading rate is imposed across the entire fault interface. The elastic stress transfer induced by fault slip is described by Equations (1) and (2), corresponding to shear stress and normal stress, respectively, under the radiation damping assumption [1]:
where \(V_{pl}\) is the imposed tectonic slip rate, \(\mu\) is the shear modulus, \(c_s\) is the shear wave speed, and \(u_j\) is the slip at the j-th element. The kernels \(k_{ij}^s\) and \(k_{ij}^N\) represent the shear and normal stiffness matrices, respectively. The last term in Equation () captures radiation damping and approximates inertial effects, which is adopted to avoid the unbounded slip velocity that would otherwise develop as a consequence of instability in a quasi-static model [1].
To compute \(k_{ij}^s\) and \(k_{ij}^N\), we employ analytical formulas for static stress induced by triangular dislocations in a homogeneous elastic full-space and half-space, as described by [2]. Since our objective is to simulate three-dimensional complex non-planar fault geometries, optimizations specific to planar faults, such as constructing the stiffness matrix in the Fourier domain [1] and leveraging translational invariance to compute stresses as convolutions using the Fast Fourier Transform, are not applicable. Instead, we utilize CPU-based multiprocessing or MPI to accelerate the computation of Green’s functions required for generating the stiffness matrix.
To construct the differential equations, we take the time derivatives of Equations () and (), while accounting for the external stress loading.
where \(\dot{\tau}_i\) and \(\dot{\sigma}_i\) represent the tectonic loading rates for shear and normal stresses on the i-th fault cell, respectively.
To solve the differential Equations () and (), we incorporate boundary conditions governed by the laboratory-derived rate- and state-dependent friction (RSF) law [3, 4]. The friction coefficient is given by a regularized aging-law formulation as
where \(d_c\) represents the characteristic slip distance, \(V_0\) the reference slip rate, \(f_0\) the reference friction coefficient, and \(\theta\) the state variable. The parameters \(a\) and \(b\) describe the direct and evolutionary effects of shear resistance during and following a velocity step.
To simplify the formulation, we replace the state variable \(\theta\) with a transformed variable \(\psi\),
The transformed friction relation then becomes
and the corresponding state evolution equation is
We now return to Equation (). The time derivative of slip rate \(dV_i/dt\) can be expressed using the chain rule as
Substituting this relation into Equation () yields the final expression for the shear stress evolution,
The shear stress is further decomposed into strike-slip and dip-slip components, denoted by \(\tau_{1}\) and \(\tau_{2}\), with corresponding slip rates \(V_1\) and \(V_2\).
For the strike-slip component,
and for the dip-slip component,
where the partial derivatives are given by
We use the backslip method [5]) with a plate rate \(V_{pl}\) for plate motion loading, such that \(V_{1,i}\) and \(V_{2,i}\) can be replaced by \(V_{1,i}-V_{pl,i}\) and \(V_{2,i}-V_{pl,i}\).
By substituting Equations (14) to (19) into Equations (12) and (13), along with Equations (), (), (12), and (13), we obtain a system of ordinary differential equations (ODEs) of dimension \(4N\):
We solve these ODEs using the Dormand-Prince 5th-order Runge–Kutta method with adaptive time stepping ([5]). After each iteration, other important variables such as slip velocity, shear traction amplitude, and rake angle are updated by the following formulas:
To implement adaptive time stepping, the step size for the next iteration \(h_{n+1}\) is calculated based on the relative error between the 4th- and 5th-order Runge-Kutta formulas:
where the safety factor \(S = 0.9\) and \(\epsilon_0 = 10^{-4}\) is the set threshold for desired precision. The relative error is computed as
Here, \(y_{n+1}^*\) is the result of the fifth-order computation, and \(y_{n+1}\) is the result of the fourth-order computation. For each Runge–Kutta iteration, we first check if \(\frac{\epsilon_0}{\epsilon_k} < 1.0\). If it is, we update the time step using Equation (27) and then constrain \(h_{n+1} = \min(1.5 h_n, h_{n+1})\). Otherwise, we update the step size using Equation (27) and then constrain \(h_{n+1} = \max(0.5 h_n, h_{n+1})\). The Runge-Kutta iteration is re-executed until the condition becomes less than 1.0 or the maximum number of iterations is reached.
To ensure numerical resolution of rupture, we monitor two key physical length scales. The first is the process zone size \(\Lambda\), given by:
which characterizes the breakdown zone near the rupture front. The constant \(C\) is equal to \(9 \pi/32\) ([7]). Three-dimensional dynamic rupture simulations by [8] demonstrated that a resolution of at least \(\Lambda/\Delta x = 3--5\) is required to adequately capture the physical features of rupture propagation.
The second critical length scale is the nucleation size \(h^*\), defined as ([9, 10, 11]):
This scale governs the minimum size of the VW patch required for spontaneous nucleation. These two length scales (\(\Lambda\), \(h^*\)) must be appropriately resolved by the mesh to ensure physically meaningful and numerically stable earthquake cycle simulations.
Fluid diffusion equation and Dilatancy Law
We model earthquake cycles with 3-D elasticity, rate-state friction, and a dilatancy law where porosity evolves toward steady state over distance \(d_c\), using BIEM coupled with Finite Difference Method (FDM). Following [12] and [13], we assume a constitutive equation for the inelastic change in porosity \(\phi\), including both dilatancy and compaction. We associate dilatancy/compaction with changes in the average lifetime of asperity contacts within the fault gouge, such that
Where \(\epsilon\) represents the empirically derived constant of order \(10^{-4}\), based on [14] experiments. Above steady state, that is for \(\theta > d_c / V\), \(\theta\) decreases (6), and the gouge dilates, while below steady state, \(\theta\) increases and the gouge compacts.
To investigate the role of dilatancy in earthquake cycles we consider coupled friction, dilatancy and pore fluid flow. We consider homogeneous diffusion model which accurately models fault‐normal flow with diffusivity \(C_{hyd}\). We assume dilatancy greatly dominates effects of temperature \(T\) and pore pressure \(p\) variation on porosity change within the thin shearing layer \(h\). Neglecting pore fluid flow parallel to the fault, for the same reason that heat flow in this direction is negligible, changes in pore pressure in the rock surrounding the shear zone is given by [13] and [15]
Where hydraulic diffusivity \(C_{hyd} = \kappa/{\eta \beta}\), \(\kappa\) is the permeability, \(\eta\) is pore fluid viscosity and \(\beta\) is compressibility of the fluid and the pore space. \(\Lambda\) is the thermal pressurization coupling parameter, equal to the ratio of thermal expansivity to compressibility. If we ignore the temperature requirement, such a simplified diffusion equation yeild
Thermal Pressurization
Thermal pressurization occurs when fluids within the fault heat up, expand, and pressurize during dynamic rupture, reducing the effective normal stress [16, 17]. The thermal pressurization effect is governed in our model by the following coupled differential equations for pressure (33) and temperature evolution [17]:
with boundary condition if only considering thermal pressurization:
Or implementing coupling thermal pressurization and dilatation:
where \(T\) is the temperature of the pore fluid, \(c_{hy}\) is the hydraulic diffusivity, \(\alpha_{th}\) is the thermal diffusivity, \(\tau V\) is the source of shear heating distributed over the shear zone of half-width \(w\), \(\rho c\) is the specific heat, \(y\) is the distance normal to the fault plane, and \(\Lambda\) is the coupling coefficient that gives pore pressure change per unit temperature change under undrained conditions.
Dilatancy arises from an increase in porosity, which causes a drop in pore fluid pressure and, consequently, a rise in effective normal stress. Thermal pressurization, by contrast, induces the opposite effect. As such, these represent a fundamental trade-off in fault mechanics.
Coupled solution of friction mechanics and diffusion equation using BIEM and FDM
The coupling between the frictional relation and pore pressure is incorporated by modifying Equation (8) as
Accordingly, the chain rule must be corrected to
With this modification, the corresponding Equation (11) becomes
The Equations (12) and (13) should be revised in the same manner. Furthermore, in Equations (14) to (19), the normal stress \(\sigma\) must be replaced by the effective normal stress \(\sigma - p\).
The problem now becomes solving the ordinary differential equations system (), (), modified (12) and (13), as well as the diffusion Equation (34). The first four differential equations are still solved using the Runge-Kutta method, which interacts with the diffusion equation through \(p\) and \(dp/dt\), while the diffusion equation is solved using finite difference method, which interacts with the friction mechanics through the state variable (Equation (32)). Then multi-physics coupling is ultimately solved iteratively using the partitioned approach.
Near the fault it is important that the discretization be sufficiently fine to capture the steep gradient in \(p\). To achieve this we make the following change of coordinate between \(y\) and \(z\):
Where \(y\) is fault-normal distance. This change of coordinate has the effect of making the mesh dense near the fault and sparse near \(y = y_\infty\). \(y_\infty\) is set to be the distance 10 m far away from the fault plane and has background pore pressure. The constant \(c\) is set to \(10^{-2}\) to yield good results.
Following the change of coordinate, the system of equations (34) is converted to [13]
We discretize the PDE and boundary conditions (43) in space, letting \(\delta = \Delta z / 2\),
for \(k = 0, 1, \ldots, K\). The discretization (43) is a second-order-accurate conservative discretization of the gradient of the flux function \(e^{-z} p_z\). The discretization of the Neumann boundary condition (48) is a second-order-accurate approximation centered around \(k = 0\). Note that the ghost variable \(p_{-1}\) is eliminated when (48) is introduced into (46).
We next consider the method for time stepping the system of equations. Let \(p^{n}_{km}\) be the value of \(p\) at the \(k\)-th point in the \(y\) direction and the \(m\)-th point in the \(x\) direction, at the \(n\)-th time step. For simplicity in presentation we illustrate the time stepping procedure for the spatially uniform, rather than log discretization. Equations (43) and (44) are discretized in time as:
where \(m = 1, \ldots, M\) and \(k = 1, \ldots, K\). Note that the equations for \(p\) are implicit in that pore pressure at time step \(n+1\) depends on \(p^{n+1}\). An important feature is that for each position along the fault (indexed by \(m\)), the pore pressure along the fault-normal profile depends only on the quantities at index \(m\). Thus, the pore pressures on the fault are only coupled through the friction/elasticity equations. The finite difference computations along the fault therefore decouple, such that \(M\) small systems of equations (with \(K\) elements) are solved at each time step using MPI, rather than one large system of equations. This is vastly more efficient than solving the full implicit equations.
We can solve the temperature-dependent diffusion equations using nearly identical procedural steps. This involves a staggered coupling scheme to iteratively resolve the distinct equations: first, apply the finite difference method to Equation (36), capturing how variations in stress and slip velocity drive temperature evolution; next, leverage the temperature rate of change to solve Equation (35) via finite difference discretization; then, incorporating the coupled pore pressure Equation (39), employ the boundary integral equation method to solve ODE Equation (20), thereby determining the slip rate and shear stress; finally, advance to Equation (36) for the subsequent time step, repeating the cycle as needed.
Hierarchical Matrix Compression and MPI Parallelization in PyQuake3D
According to [6], PyQuake3D implements a
Python-based H-matrix framework from the ground up. The implementation,
contained in the Hmatrix.py module, supports MPI-based parallel
acceleration and is designed with modularity, making it easily separable and
adaptable for use in other applications.
The core idea of the H-matrix is to apply low-rank approximation to far-field submatrices while keeping the dense near-field submatrices. Therefore, the essential purpose is to decompose the original matrix in a reasonable and efficient manner and to identify the submatrices suitable for low-rank approximation. The structure of the H-matrix is built upon a cluster tree and a block tree. The construction begins with generating a cluster tree based on the element index, which is then used to form the block cluster tree through pairwise combinations of the clusters. The implementation of H-matrices in PyQuake3D includes four parts: cluster tree construction, block cluster tree generation, low-rank approximation, as well as MPI acceleration.
Cluster and Block tree construction
A simple method of building a cluster tree is based on geometry-based splittings of the index set. The unit coordinates in 3D space are the basis \(\{e_x, e_y, e_z\}\) of the canonical unit vectors. The following algorithm will split a given cluster \(\tau \subset I\) into two sons such that the points with canonical coordinate \(x_i\) are separated by a hyper-plane.
Procedure Split(τ, var τ_1, var τ_2)
# Choose a direction for geometrical splitting of the cluster τ
for j := 1 to d:
α_j := min{ <e_j, x_i> : i ∈ τ } # <·,·> is the ℝ^d Euclidean product, d=3
β_j := max{ <e_j, x_i> : i ∈ τ }
j_max := argmax{ β_j - α_j : j ∈ {1,...,d} }
# Split the cluster τ in the chosen direction
γ := (α_{j_max} + β_{j_max}) / 2
τ_1 := ∅; τ_2 := ∅
for i ∈ τ:
if <e_{j_max}, x_i> ≤ γ:
τ_1 := τ_1 ∪ {i}
else:
τ_2 := τ_2 ∪ {i}
end for
end procedure
The cluster tree can be used to define a block tree by forming pairs of clusters recursively, and an admissibility condition is constructed by the following procedure (Algorithm Listing 1).
Algorithm: Build BlockTree
Procedure BuildBlockTree(τ × σ)
begin
if τ × σ is not admissible and |τ| > C_leaf and |σ| > C_leaf then
begin
S(τ × σ) := { τ′ × σ′ : τ′ ∈ S(τ), σ′ ∈ S(σ) }
for τ′ × σ′ ∈ S(τ × σ) do
BuildBlockTree(τ′ × σ′)
end for
end
else
S(τ × σ) := ∅
end if
end
For a pair of index clusters \((τ, σ)\), the corresponding submatrix is \(A_{τ, σ}\). These matrix blocks are organized into a block cluster tree, which guides the hierarchical representation of \(A\). If the clusters \(t\) and \(s\) are both non-leaf nodes with children \(t₁, t₂\) and \(s₁, s₂\) respectively, the submatrix \(A_{ts}\) can be further decomposed into four submatrices (Fig. 1 a).
Fig. 1 Construction of hierarchical matrix speed up by MPI
Admissibility Condition
Matrix blocks \(A_{τ, σ}\) are classified into admissible and inadmissible based on the geometric configuration of \(τ\) and \(σ\). We need an admissibility condition that allows us to check if a candidate \((τ × σ)\) allows for a suitable low rank approximation (Algorithm Listing 2).
A relatively general and practical admissibility condition for clusters in \(ℝ^d\) can be defined by using bounding boxes: We define the canonical coordinate maps
for all \(k ∈ {1, …, d}\) (d = 3 in 3D space). The bounding box for a cluster \(τ\) is then given by
Obviously, \(a_{τ,k}\) and \(b_{τ,k}\) are the minimum and maximum value in the k-th dimension of the coordinate set \(Ω_τ\), we have \(Ω_τ ⊆ Q_τ\), so we can define the admissibility condition
We can compute the diameters and distances of the boxes by
and
Low-Rank Approximation of Admissible Blocks
When calculating the stress Green’s function, we need to avoid constructing the full dense BEM matrix by Low-Rank Approximation. This can be helpful for reducing memory costs and, in some situations, actually results in a faster solver too. Singular value decomposition (SVD) is an extremely efficient approximation, but it still suffers from the need to compute the entire matrix block in the first place, an \(O(n^2)\) operation!
The most useful solution for our setting is the adaptive cross approximation (ACA) method [19, 20], but most real-world application use either ACA with partial pivoting or the ACA+ algorithm [21]. The basic idea of ACA+ is to approximate a matrix with a rank 1 outer product of one row and one column of that same matrix, and then iteratively use this process to construct an approximation of arbitrary precision. ACA+ uses orthogonal projections and recompression to better control the error and avoid poor pivot choices, and improves the stability and accuracy of the standard ACA.
Parallelization of H-matrix Construction and Matrix-Vector Multiplication with MPI
We construct the cluster tree, block cluster tree, and establish the overall H-matrix framework. This includes the initial distribution of the index sets and the assignment of matrix blocks. Once the hierarchical structure is built, the matrix blocks are distributed across different MPI processes for parallel computation of elements (e.g., MPI_send, MPI_recv). We adopt a dynamic task allocation strategy in MPI to mitigate load imbalance issues that may arise from static task assignment (Fig. 1 d).
Each process is responsible for computing the entries of its assigned matrix blocks. For admissible blocks, a low-rank approximation is performed using the ACA algorithm. For non-admissible blocks, typically corresponding to leaf nodes in the block cluster tree, are the full dense matrix computed by evaluating all pairwise Green’s function interactions between source and target elements (Fig. 1 c).
During matrix-vector multiplication, each process independently computes the product of its local matrix blocks with the corresponding
portion of the input vector. The final global result vector is then obtained by summing the local contributions across all processes (MPI_reduce) (Fig. 1 e).
H-matrix and Lattice H-matrix
In the conventional H-matrix approach, the MPI_Allreduce (or the Reduce-Broadcast cycle) acts as a “stop-the-world” barrier, where communication costs eventually outpace the actual floating-point math as you scale up.
The transition to a Lattice H-matrix (or 2D-topology H-matrix) effectively localizes these communications. Here is the completion of the comparison, detailing the structural and algorithmic differences:
H-Matrix (1D/Global Layout):In a standard implementation, the matrix-vector multiplication (H-Matvec) often treats the slip rate vector as a global entity. Every process involved in the dot product must contribute its local result to a global sum.
Scope: Global. Every process communicates with every other process.
Barrier: The MPI_Reduce involves all P processes, creating a massive synchronization overhead that scales poorly with high core counts.
Lattice H-Matrix (2D/Local Layout):By adopting a 2D MPI Cartesian grid, the Lattice approach partitions the workload such that processes are grouped into row communicators and column communicators.
Scope: Sub-communicators. Summation is restricted to \(P_{row}\) processes.
Feasibility: Because the physical domain is discretized into a lattice, the interaction between sub-blocks is localized. Slip rate updates only need to be synchronized across diagonal processes or specific neighbors, rather than the entire cluster.
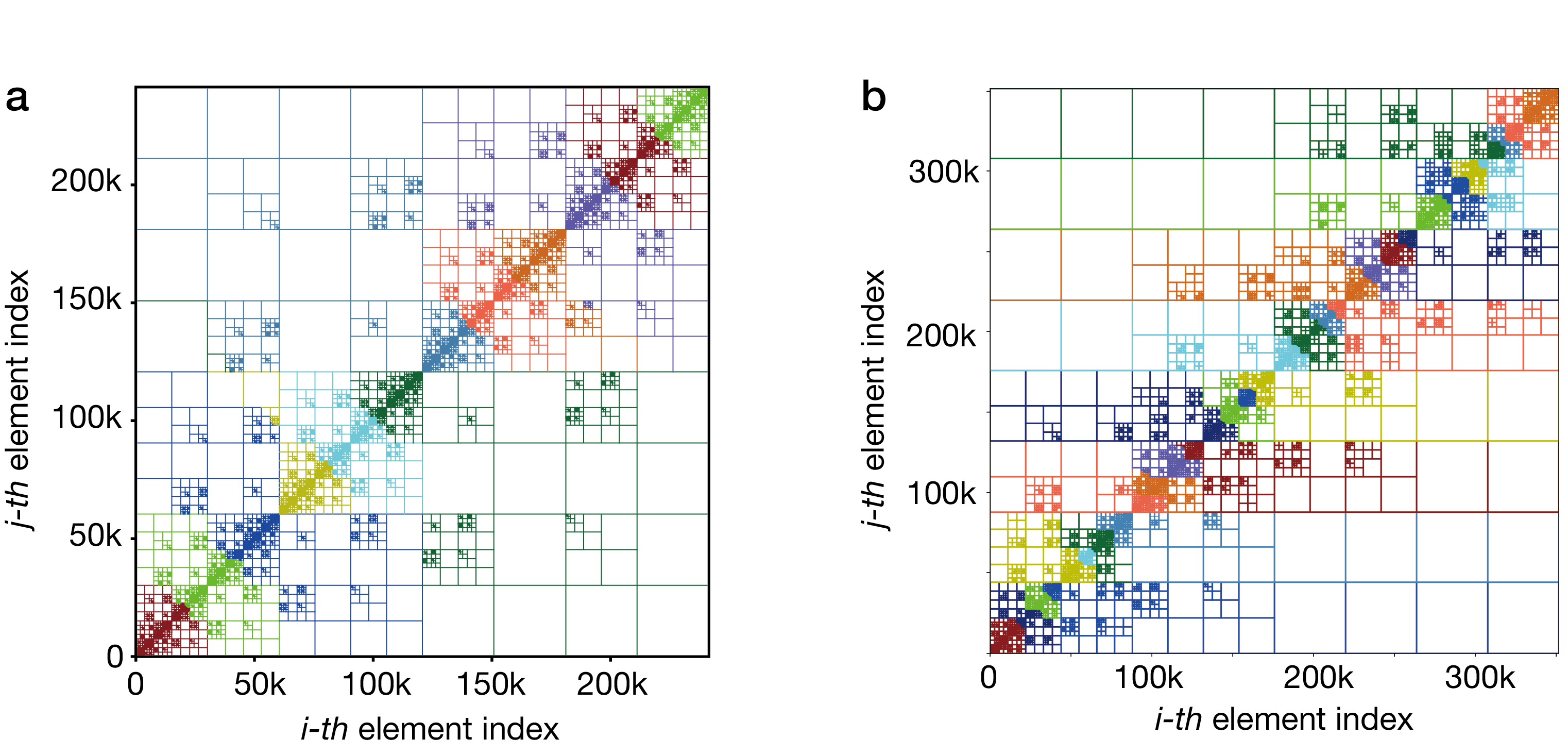
Fig. 2 Comparison of structure of H-Matrix and Lattice H-Matrix.(a) H-Matrix. All processes participate in the global decomposition of the H-matrix. (b) Lattice H-Matrix. The Lattice H-Matrix partitions the matrix into sub-blocks that are distributed across a 2D grid of MPI processes, allowing for more localized communication patterns and improved scalability.Balance the distribution of H-submatrices across all processes within each row communicator.
Definitions of Slip Directions and Coordinate Systems
The rake angle is defined as the angle between the fault slip vector and the fault strike direction within the fault plane. In seismology, the strike direction is conventionally defined: when facing the dip direction of the fault plane, the strike is taken to be to the observer’s right—this follows the right-hand rule. In PyQuake3D, Based on the code you provided, here is a clear explanation of how you are building a Local Coordinate System for a triangular fault element, which is determined by the ordering of the element’s nodes—either clockwise or counterclockwise.
To get the defined strike-slip direction for each element, we first calculate the normal vector of the element in the global coordinate system by
By crossing the vertical unit vector \(\vec{e}_z\) with the fault normal \(\vec{e}_3`(:numref:`strike_vector\)), the code finds a vector that is both in the plane (perpendicular to the normal) and horizontal (perpendicular to \(\vec{e}_z\)), which is defined as the strike-slip direction. Then the local coordinate system can be obtained by
Fig. 3 b and c show that the definition of strike slip and dip slip directions obviously depends on the ordering of nodes, so when modeling, we need to first clarify the ordering direction of nodes, and then determine the definition of fault slip direction.
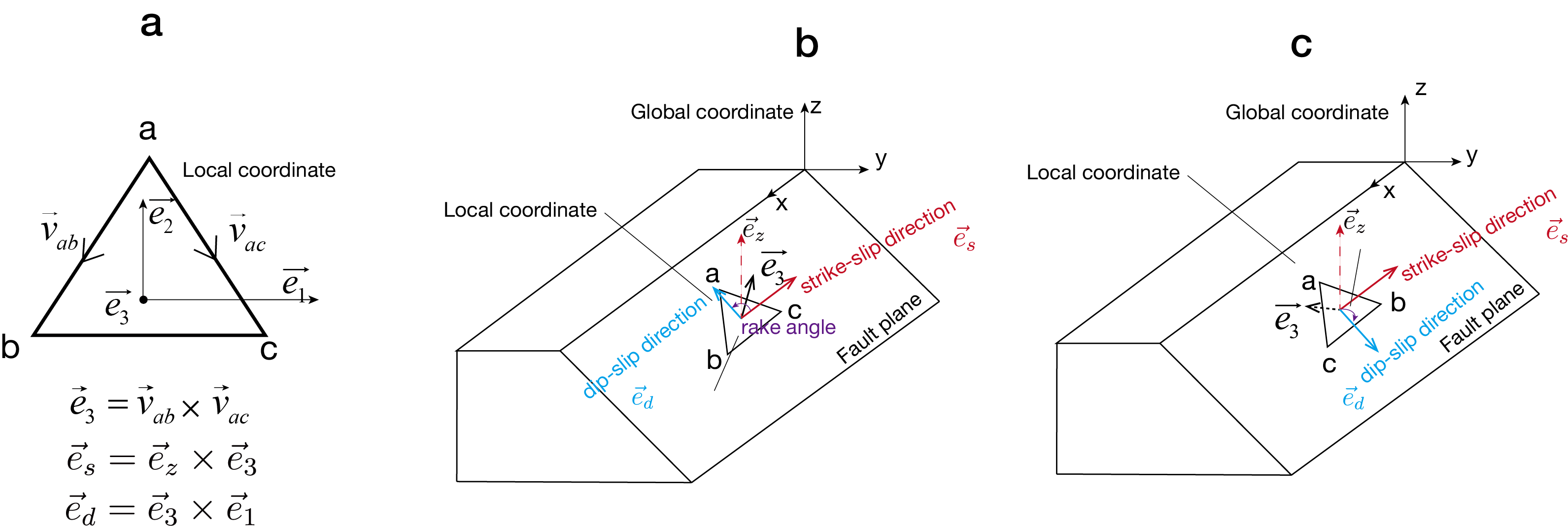
Fig. 3 Definition of strike-slip and dip-slip direction.(a) Calculation of normal vector or z-vector in element local coordinate system \(\vec{e}_3\). By crossing the vertical unit vector \(\vec{e}_Z\) with the fault normal \(\vec{e}_3\), the code finds a vector that is both in the plane (perpendicular to the normal) and horizontal (perpendicular to \(\vec{e}_Z\)) (b) Looking from the negative direction of the z-axis, the unit nodes are counterclockwise, and the element normal is outwards. The strike-slip direction is defined as the negative x direction, and the y direction can be obtained by cross-producting the z and x unit vectors. (c) Looking from the negative direction of the z-axis, the unit nodes are clockwise, and the element normal is inwards. The dip-slip direction is defined as the down dip direction.
Coordinate system
In post-processing, we need to do transforms between local and global coordinates for some vector results, such as slip direction. Base on the relationship in Fig. 3 d and e, the transform from local coordinates to global coordinates can be obtained by coordinate rotation.
Where x is a vector of local coordinates and X is a vector of global coordinates.
—
References
James R Rice. Spatio-temporal complexity of slip on a fault. Journal of Geophysical Research: Solid Earth, 98(B6):9885–9907, 1993.
Mehdi Nikkhoo and Thomas R Walter. Triangular dislocation: an analytical, artefact-free solution. Geophysical Journal International, 201(2):1119–1141, 2015.
James H Dieterich. Modeling of rock friction: 2. simulation of preseismic slip. Journal of Geophysical Research: Solid Earth, 84(B5):2169–2175, 1979.
Andy Ruina. Slip instability and state variable friction laws. Journal of Geophysical Research: Solid Earth, 88(B12):10359–10370, 1983.
Elías Rafn Heimisson. Crack to pulse transition and magnitude statistics during earthquake cycles on a self-similar rough fault. Earth and Planetary Science Letters, 537:116202, 2020.
William H. Press, Saul A. Teukolsky, William T. Vetterling, and Brian P. Flannery. Numerical Recipes: The Art of Scientific Computing. Cambridge University Press, Cambridge, 3rd edition, 2007.
Nadia Lapusta and Yi Liu. Three-dimensional boundary integral modeling of spontaneous earthquake sequences and aseismic slip. Journal of Geophysical Research: Solid Earth, 2009.
Steven M Day, Luis A Dalguer, Nadia Lapusta, and Yi Liu. Comparison of finite difference and boundary integral solutions to three-dimensional spontaneous rupture. Journal of Geophysical Research: Solid Earth, 2005.
James R Rice and Andy L Ruina. Stability of steady frictional slipping. Journal of applied mechanics, 50(2):343–349, 1983.
Allan Mattathias Rubin and J-P Ampuero. Earthquake nucleation on (aging) rate and state faults. Journal of Geophysical Research: Solid Earth, 2005.
Ting Chen and Nadia Lapusta. Scaling of small repeating earthquakes explained by interaction of seismic and aseismic slip in a rate and state fault model. Journal of Geophysical Research: Solid Earth, 2009.
Paul Segall and James R Rice. Dilatancy, compaction, and slip instability of a fluid-infiltrated fault. Journal of Geophysical Research: Solid Earth, 100(B11):22155–22171, 1995.
Paul Segall, Allan M Rubin, Andrew M Bradley, and James R Rice. Dilatant strengthening as a mechanism for slow slip events. Journal of Geophysical Research: Solid Earth, 2010.
Chris Marone, C Barry Raleigh, and CH Scholz. Frictional behavior and constitutive modeling of simulated fault gouge. Journal of Geophysical Research: Solid Earth, 95(B5):7007–7025, 1990.
Paul Segall and James R Rice. Does shear heating of pore fluid contribute to earthquake nucleation? Journal of Geophysical Research: Solid Earth, 2006.
James R Rice. Heating and weakening of faults during earthquake slip. Journal of Geophysical Research: Solid Earth, 2006.
Hiroyuki Noda and Nadia Lapusta. Three-dimensional earthquake sequence simulations with evolving temperature and pore pressure due to shear heating: effect of heterogeneous hydraulic diffusivity. Journal of Geophysical Research: Solid Earth, 2010.
Steffen Börm, Lars Grasedyck, and Wolfgang Hackbusch. Introduction to hierarchical matrices with applications. Engineering analysis with boundary elements, 27(5):405–422, 2003.
Mario Bebendorf. Approximation of boundary element matrices. Numerische Mathematik, 86:565–589, 2000.
Sergej Rjasanow and Olaf Steinbach. Approximation of boundary element matrices. The Fast Solution of Boundary Integral Equations, pages 101–130, 2007.
Lars Grasedyck. Adaptive recompression of-matrices for bem. Computing, 74:205–223, 2005.